
- Gợi ý từ khóa:
- gõ Tiếng Việt có dấu hoặc không dấu đều được
Anpero đã áp dụng Kafka vào những chức năng nào cho web của bạn
Khi bạn sử dụng website trên hệ thống do Anpero thiết kế có nhiều chức năng đã được áp dụng công nghệ này đảm bảo tốc độ, độ ổn định và tin cậy gấp hàng trăm nghìn lần các phương thức cũ
Các chức năng điển hình:
1. Kafka là gì?
Kafka là một hệ thống message pub/sub phân tán. Các bên thực hiện public dữ liệu được gọi là producer, bên subscribe và nhận dữ liệu theo các topic được gọi là consumer. Kafka có khả năng truyền một lượng lớn các message trong thời gian thực. Ngoài ra, Kafka cung cấp cơ chế offset cho phép các consumer có thể đọc lại các tin nhắn theo một hàng đợi được lưu trên ổ đĩa đảm bảo an toàn.
Kafka cung cấp một cơ chế cluster sử dụng zookeeper để tạo dựng và duy trì kết nối giữa các node. Các message sẽ được replicate trong cluster giúp phòng tránh mất dữ liệu.
2. Các khái niệm cơ bản
Cấu trúc Kafka bao gồm các thành phần sau:
PRODUCER: Kafka lưu, phân loại message theo topic, sử dụng producer để publish message vào các topic. Dữ liệu được gửi đến partition của topic lưu trữ trên Broker.
CONSUMER: Kafka sử dụng consumer để subscribe vào topic, các consumer được định danh bằng các group name. Nhiều consumer có thể cùng đọc một topic.
TOPIC: Dữ liệu truyền trong Kafka theo topic, khi cần truyền dữ liệu cho các ứng dụng khác nhau thì sẽ tạo ra các topic khác nhau.
PARTITION: Đây là nơi dữ liệu cho một topic được lưu trữ. Một topic có thể có một hay nhiều partition. Trên mỗi partition thì dữ liệu lưu trữ cố định và được gán cho một ID gọi là offset. Trong một Kafka cluster thì một partition có thể replicate (sao chép) ra nhiều bản. Trong đó có một bản leader chịu trách nhiệm đọc ghi dữ liệu và các bản còn lại gọi là follower. Khi bản leader bị lỗi thì sẽ có một bản follower lên làm leader thay thế. Nếu muốn dùng nhiều consumer đọc song song dữ liệu của một topic thì topic đó cần phải có nhiều partition.
BROKER: Kafka cluster là một set các server, mỗi một set này được gọi là 1 broker
ZOOKEEPER: được dùng để quản lý và bố trí các broker.
3. Tại sao Kafka lại nhanh đến vậy?
Gửi dữ liệu có độ trễ thấp: Hầu hết các hệ thống dữ liệu truyền thống sử dụng bộ nhớ truy cập ngẫu nhiên (RAM) để lưu trữ dữ liệu, vì RAM cung cấp độ trễ cực kỳ thấp. Tuy nhiên RAM rất đắt đỏ đặc biệt khi lượng dữ liệu là vô cùng lơn. Vì vậy, Kafka không dùng RAM để có thể gửi tin nhắn có độ trễ thấp, mà sử dụng 2 thiết kế là Sequential I/O và Zero Copy Principle.
Sequential I/O: Kafka sử dụng filesystem để lưu trữ và cache tin nhắn. Chúng ta biết rằng disk chậm hơn nhiều so với RAM trong thời gian tìm kiếm thông tin được lưu trữ. Kỹ thuật Sequential I/O giải quyết điều này với thiết kế append-only log, một cấu trúc dữ liệu có thứ tự. Mỗi khi producer gửi tin nhắn đến queue thành công, offset của tin nhắn đó sẽ được gửi lại. Giá trị offset tăng dần từ giá trị ban đầu 0 và giúp producer biết được nơi cần viết tin nhắn khi cần. Tương tự, consumer luôn lưu trữ giá trị offset giúp việc tìm kiếm tin nhắn cần đọc trở nên nhanh hơn nhiều.
Zero Copy Principle: Để hiểu về kĩ thuật này, chúng ta cần hiểu điều gì xảy ra khi 1 ứng dụng muốn gửi dữ liệu từ disk qua 1 network. Theo cách truyền thống, dữ liệu sẽ được Kernal đọc và đẩy đến ứng dụng. Ứng dụng tiếp tục viết dữ liệu vào socket để sau đó gửi qua network. Với Zero Copy Principle, Kernal sẽ đọc dữ liệu trực tiếp dữ liệu từ disk và viết thẳng vào socket. Điều này giúp giảm thiểu các tác vụ trung gian và tối ưu hoạt động của Kernal.
4. Tại sao chúng tôi sử dụng Kafka?
Có rất nhiều ưu điểm chúng ta có thể nhắc đến khi được hỏi lý do tại sao lại chọn sử dụng Kafka. Dưới đây là một vài nguyên nhân chúng ta có thể nhắc đến:
5. Kafka có thể được sử dụng như thế nào?
Cập nhật tin tức nhanh nhất và mới nhất
Bạn đang kinh doanh tại Nam Định và cần một website chuyên nghiệp, chuẩn SEO, dễ sử dụng để thu hút khách hàng?
Xem thêm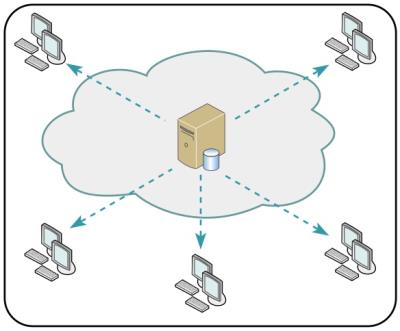
Một trong những thách thức phổ biến nhất khi cố gắng cải thiện hiệu suất của website
Xem thêm
Chấp nhận thanh toán trả góp giúp bán được nhiều hàng hơn, tăng cạnh tranh so với đối thủ
Xem thêm
Trong SEO, Structured Data là một cách tổ chức thông tin trên website theo một định dạng tiêu chuẩn, giúp công cụ tìm kiếm như Google, Bing
Xem thêm
Giải pháp quản lý website tập trung, tạo website miễn phí trong 5 phút với các giao diện tạo sẵn được kiểm tra tỷ mỉ trên mọi thiết bị. Chi phí vận hành tập trung được tối ưu, với giá chỉ bằng cốc chè đá/ngày
Xem thêm
Công việc này bao gồm việc nhập liệu sản phẩm, bài viết, trang dịch vụ, tin tức, và các nội dung khác theo yêu cầu của bạn
Xem thêm
Đúng vậy! Sở hữu và duy trì website càng lâu càng có lợi, đặc biệt là trong các khía cạnh sau:
Xem thêm
Việc sở hữu một website vẫn mang lại nhiều lợi ích thiết thực, ngay cả khi có nhiều nền tảng bán hàng mạnh mẽ khác. Dưới đây là một số lý do và lợi ích của việc có website riêng
Xem thêm